某笔音频提取实现以及结构分析(附demo)
1 前言
之前分析过m3u8的ts文件的结构,从结果来看,学到了不少东西。今天我们来分析下,某笔的音频提取,为什么不提取视频呢?因为这是webRTC技术,浏览器端的实时传输控制,可以传输任何数据类型。在某笔的一些课程中,其实看到的视频上没有视频的,只是个PPT在按照指令切换,以及画笔等,指令也是通过webRTC传输的。所以某笔中的某些课程,可能只有音频。因此我们来提取音频。
在经过N多天的研究-放弃-不甘心-放弃-继续的循环中,终于搞定了,分析过程还是挺难受的,因为有时毫无头绪。但还好没放弃。
当我们遇到难题的时候,只要我们 多分析,多思考,多百度,一定可以成功,如果不行就再来一遍。总之不要放弃。"43922983_2-分析过程">2 分析过程
分析环境以及工具:
Mac OS 12.0.1、Safari浏览器、SublimeText
分析视频地址:
aHR0cHMlM0EvL3d3dy5mZW5iaS5jb20vc3BhL3dlYmNsYXNzL2NsYXNzLzQ4MDYxMi82MDc3OTAxLzM1MTAwMC8wL3BjJTNGYml6SWQlM0Q0ODA2MTI=
2.1 观察网络请求、寻找关键部分
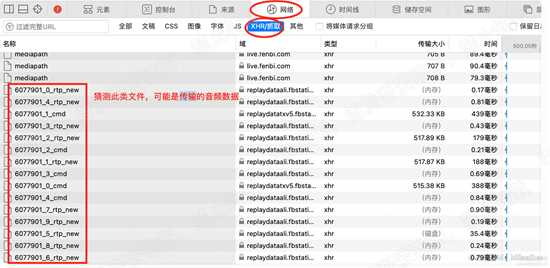
打开视频网址,打开浏览器的开发者工具,播放视频,观察网络请求。可以发现,某些文件一直增加,类似:xxxxxxx_x_rtp_new
由此猜测,音频数据可能是通过这类文件进行传输。如下图
d1.png
d1
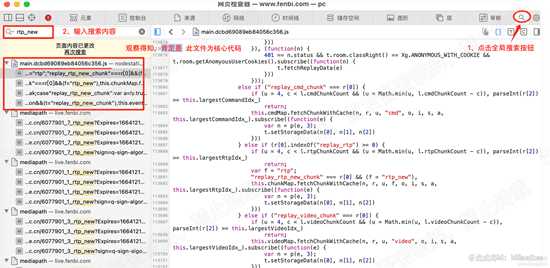
根据关键词全局搜索
刚开始可能不知道搜索什么,慢慢尝试,这里根据上面的文件名 搜索 rtp_new,如下图
d2.png
d2
2.2 根据堆栈回溯参数的来源
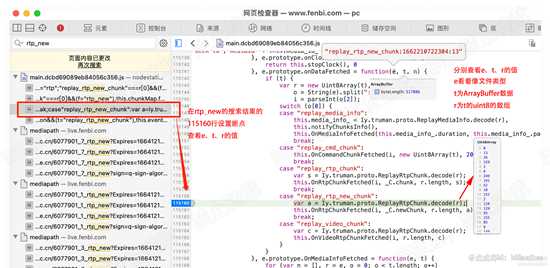
我们直接在刚搜索的rtp_new的结果的 115160行处 设置断点。并查看参数e、t、r的值。如下图
d3.png
d3
根据上图,我们大概猜测其中 t 和 r的值就是 文件的数据。 e的值可能是文件类型之类的。
为了验证,我们根据函数调用堆栈回溯,看看参数是从哪里传过来的。
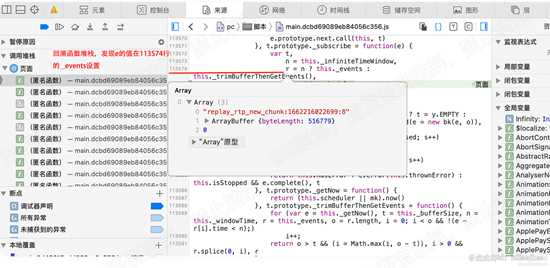
经过回溯,最后我们发现e的值, 由113574行的 this._events 设置。如下图
d4.png
d4
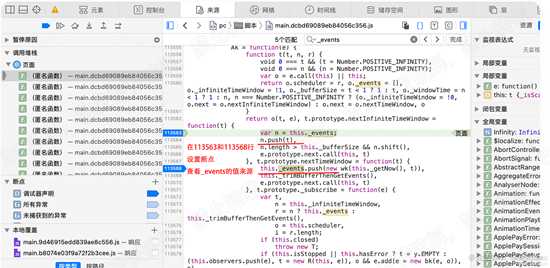
在本文件中,搜索_events 发现在113563和113568行,设置了_events的值。因此在这两处都设置断点。重执行,会发现,断点停留在113563行。
可知,_events的值,由t设置。如下图
d5.png
d5
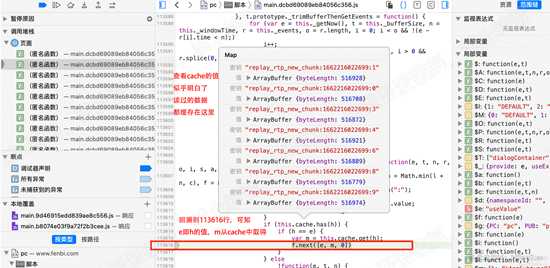
继续回溯,查看t的来源。回溯到113616行,可知 参数t的值由e决定,m是从cache中根据e取出来的值。
通过查看cache的值,可以发现 读取过的数据都缓存在cache中。观察cache中的秘钥的值,最后的数字似乎是文件索引。
如下图:
d6.png
d6
分析113613行的代码: if (this.cache.has(h))
翻译:即若cache中存在h,则从cache中取得数据。
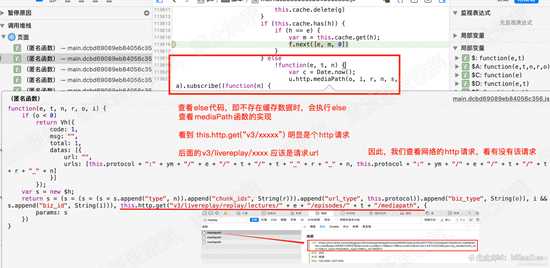
因此,当cache中不存在h时,则会执行else的代码,查看else中的 mediaPath函数,发现如下代码:
this.http.get("v3/livereplay/replay/lectures/" + e + "/episodes/" + t + "/mediapath"
显然,这是一个http请求。在 查看网络菜单下的 网络请求,我们发现 mediapath的请求url和这个差不多。如下图
d7.png
d7
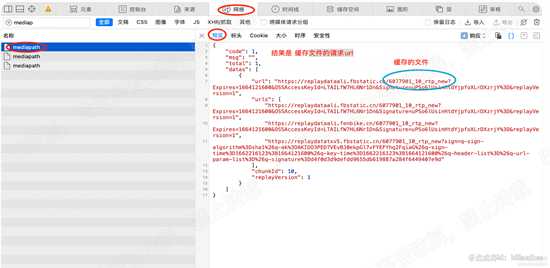
从名字来看,我们9成确定,这里就是在发送mediapath请求,在web检查器中网络菜单下,查看该请求的响应的值。
可知,该请求是获取缓存文件的请求地址。如下图
d8.png
d8
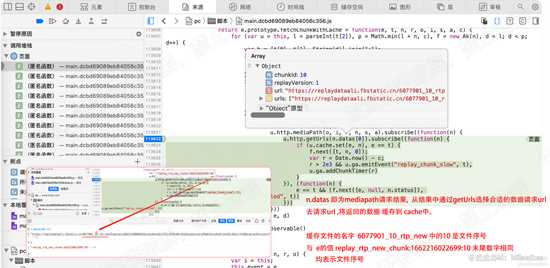
在113622行设置断点,也就是 mediapath请求的响应结果处。可知返回结果为n,其中n.datas为 媒体数据文件的请求地址。
根据该地址,获取媒体数据文件的数据,缓存到cache中,其中缓存的 key 的末尾数字,与 数据文件的名字中的数字相同,都表示文件序号。
至于如何证明,大家可以自己去看参数的传递过程。
文件名 6077901_10_rtp_new
缓存的key值 replay_rtp_new_chunk:1662216022699:10
其中,10 都表示文件序号。防止媒体数据错乱。 如下图
d9.png
d9
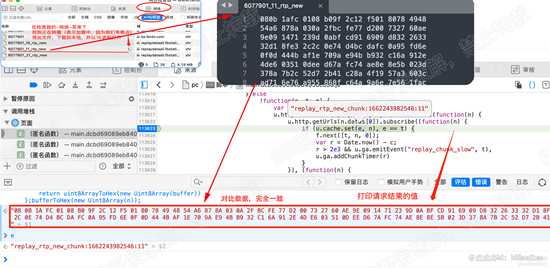
下面,将请求获取到的值以及115160行的 参数t的值,与 网络中抓包获取到文件对比下。
可以确定,内容完全相同。如下图:
d10.png
d10
至此,我们可以确定 115160行处的函数内的 e、t、r的值是什么了。
e 为数据缓存的key
t 为媒体文件的数据
r 也是媒体文件数据(uInt8类型)
总结下:
1、取数据时,若存在缓存从缓存中读取,不存在则进行mediapath请求
2、通过mediapath请求,取得媒体文件的url
3、根据文件url请求媒体文件内容,并缓存
2.3 分析文件数据,如何解码为多个数据包
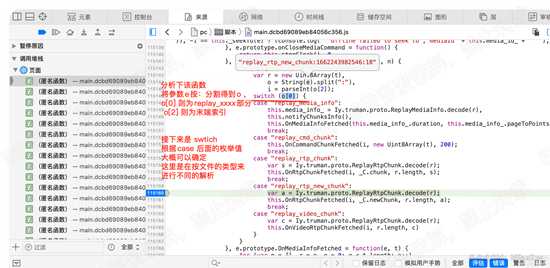
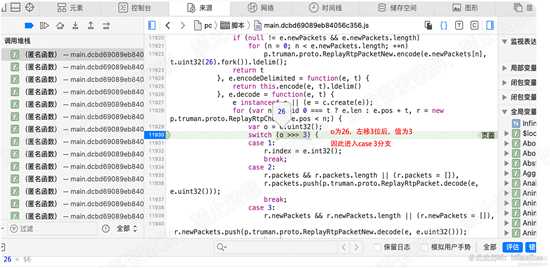
回到115160行的代码,分析该行所在的函数,参数e被按冒号切换为o, 然后switch o[2]的值,
根据case 的枚举值,我们猜测,这是在根据文件类型不同 去做不同的处理。其中 有cmd 、有video等
这里延伸下:其实cmd是在传输操作指令,本视频不存在video流,所以不会执行video分支。如下图
d11.png
d11
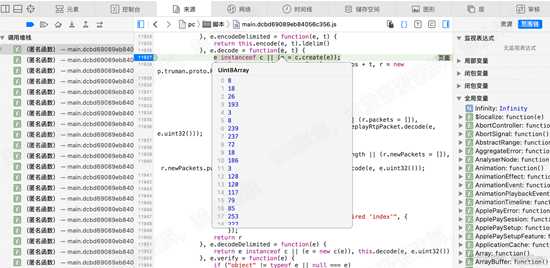
接下来分析 115160行的 decode函数。进入decode函数内部,在函数体的第一行,也就是11927行设置断点。
查看参数e的值和t的值,发现e为数据,t为空。注意,decode函数有两个参数,但调用时,只传了一个 r 过来。如下图
d12.png
d12
分析下第一行代码 e instanceof c || (e = c.create(e));
c.create的函数内容如下
function c(e) {
this.buf = e,
this.pos = 0,
this.len = e.length
}
该代码执行的结果,即生产一个对象,对象含有buf数据体,pos索引位置, len数据长度。并将结果赋给e。
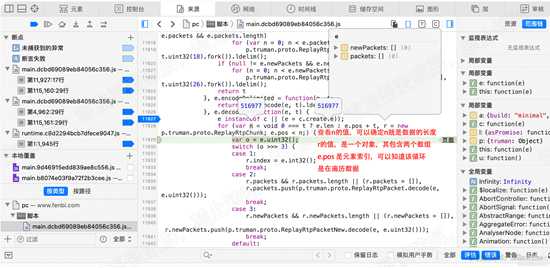
继续分析for循环、单步执行至11929行,查看n的值,以及r的值。r是个对象,包含两个数组newPackets和packets.
n是e.len的值,即数据长度,可知该循环在遍历数据。如下图:
d13.png
d13
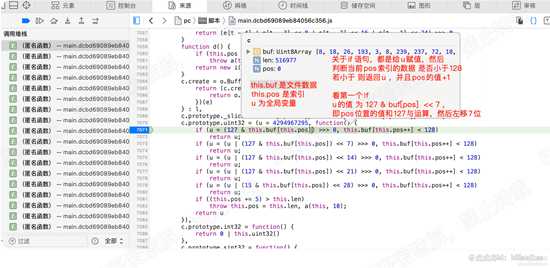
接下来看下 11929 行的e.uint32函数。进入uint32()的函数体,在函数的第一行也就是7071行,设置断点。继续执行进入该函数。
该函数,主要是在设置u的值,可以知道u是全局变量,this.buf为文件数据,this.pos为索引。如下图:
d14.png
d14
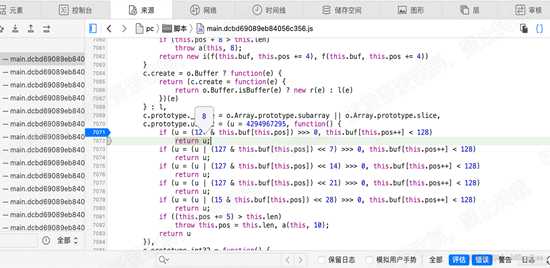
那么u的值,是如何获取的,来分析 7071行的语句
if (u = (127 & this.buf[this.pos]) > 0, this.buf[this.pos++] < 128)
拆分下,两个句子:
第一个,给u 赋值:
u = (127 & this.buf[this.pos]) > 0
翻译下:
取buf得第pos个元素,和127做与运算,然后右移0位。得到u的值。
这里pos为0,buf[0] 是的值为 8,即 u = 127 & 8 = 8
第二个,this.buf[this.pos++] < 128
this.buf[this.pos++] 与 this.buf[this.pos] 其实他们的值相同,都是取pos位置的buf的值,
区别在于前者在语句执行后,pos的值会 加1, 因为pos为对象的属性,所以每次调用该函数,pos的值都会改变。
若该值小于 128,则返回u的值。否则继续下一个if语句。
其他的if语句类同。
单步执行到7072行,可以看到 return u, u的值为8 如下图
d15.png
d15
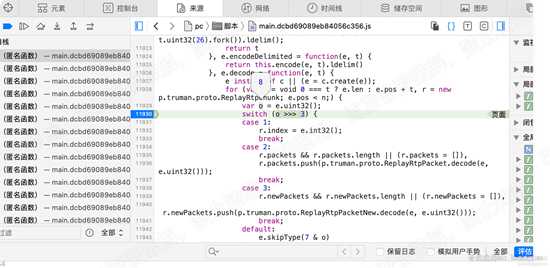
返回decode函数,在11930行设置断点,执行。可以看到e.uint32()的返回值是8,赋给变量o
然后进入switch ,将 o > 3 , 即右移3位,我们知道 8的二进制为 1000,右移3位,则为 1
d16.png
d16
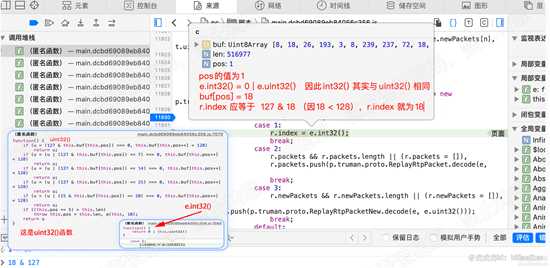
单步执行,会进入 case 1 分支,在11932行,我们查看下e的值,可以看到pos的值为1,它是在执行完uint32()函数后改变的。
分析11932行代码 r.index = e.int32();
int32()函数 其实就是 uint32() ,那么 r.index = e.uint32() , 看e.buf的值,知道 buf[1] = 18,
结合uint32()函数,可知 r.index = 18 , 由此我们猜测18为索引序号,buf[0] 即8,为固定标识。如下图
d17.png
d17
为什么会如此猜测? 因为buf[0] = 8, 然后左移3位得到1,进入switch的case 1分支得到 index的值18。
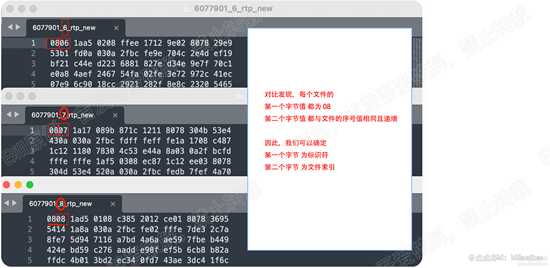
通过对比多个抓包文件,我们发现,每个文件的第一个字节都是 08, 第二个字节的值 与文件的索引值相同。如下图:
d18.png
d18
我们继续分析e.decode函数,此时 设置了r.index的值后,会进行下个循环。我们把断点重设置在11929行,然后执行。
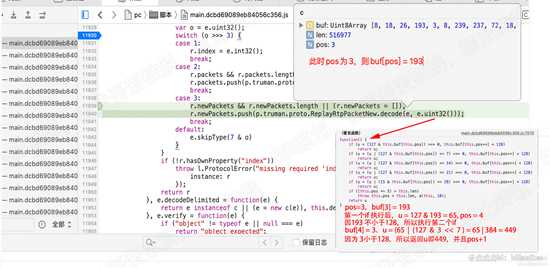
程序停留在11929行,此时猜测 e.pos的值是多少呢,应该是2,因为给index赋值的时候会调用uint32函数,且是只执行了一个if,因此自增一次。
此时 再次分析 var o = e.uint32(); 可以知道,此时的buf[pos] = buf[2] = 26, 26 小于 128,因此可以知道 o = 26 & 127 = 26
此时o为26,右移3位,26 > 3 = 3 ,因此会进入 case 3的分支。单步执行至11930行,查看o的值,的确为26。如下图:
d19.png
d19
分析case 3的代码,单步执行至 11939行,分析如下代码
r.newPackets && r.newPackets.length || (r.newPackets = []),
r.newPackets.push(p.truman.proto.ReplayRtpPacketNew.decode(e, e.uint32()));
第一行比较简单:若r.newPackets不存在,则给其赋值空数组 []
第二行是 将decode(e, e.uint32())的返回结果放入r.newPackets数组。
分析此时 e.uint32() 的返回值。 查看e的值。如下图:
d20.png
d20
分析 p.truman.proto.ReplayRtpPacketNew.decode(e, e.uint32()) 函数。
进入此函数,在第一行也就是11861行 设置断点,执行进入。可以看到t的值为449,pos为5,如下图:
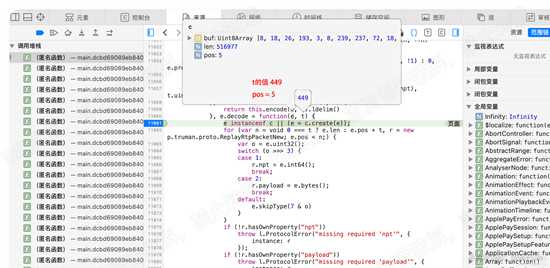
d21.png
d21
分析for循环
for (var n = void 0 === t ? e.len : e.pos + t, r = new p.truman.proto.ReplayRtpPacketNew; e.pos < n;)
由于t为449,因此 n = e.pos + t = 5+449 = 454。创建r对象,循环条件 e.pos < n
单步执行至 11864行, 查看o的值、n的值以及e.pos。可知o=8, n=454, e.pos = 6, 如下图:
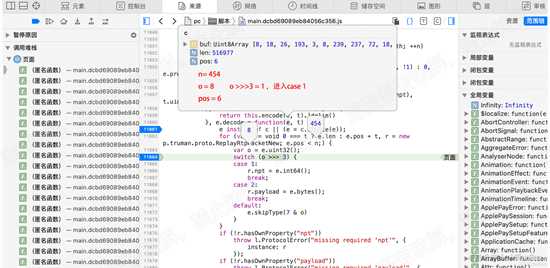
d22.png
d22
我们知道o=8,o>3 就是1,因此会进入case 1分支,我们看其内部代码
r.npt = e.int64(); 该代码是在解析 npt的值,int64()内部,我们就分析了,大家可自行查看。
单步执行至11867行。
查看 r.npt的值,以及pos的值为9。确定 int64() 函数即求npt得值,并使用了 buf[6]、buf[7]、buf[8]的3个字节的值。
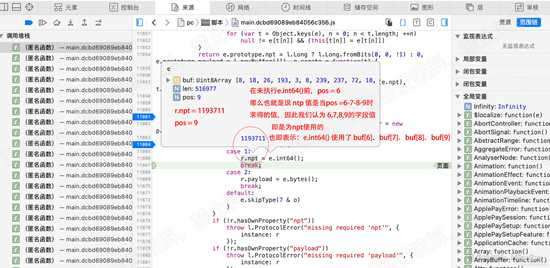
d23.png
d23
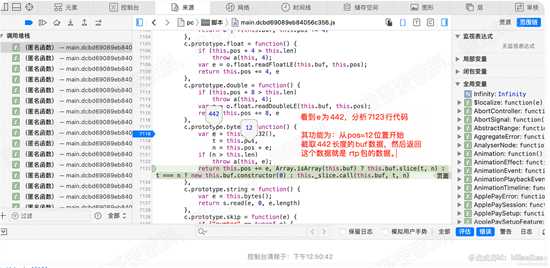
单步执行至11869行的 case 2分支:r.payload = e.bytes(); 查看此时的 pos值为 10,o为18。
进入e.bytes函数,在7118行设置断点,进入函数。查看pos的值,推算第一行e = uint23()的值。应为442. 如下图
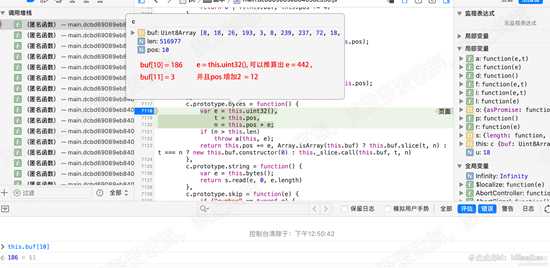
d24.png
d24
单步执行至 7123行,查看e和pos的值,分析7123行的代码:
return this.pos += e, Array.isArray(this.buf) ? this.buf.slice(t, n) : t === n ? new this.buf.constructor(0) : this._slice.call(this.buf, t, n)
该代码的功能: 截取pos开始的e长度的buf数据,然后返回。 这个数据其实就是rtp数据包(后面分析得知)。如下图
d25.png
d25
返回decode函数,在11879行,设置断点。执行进入。
查看r.payload的值,我们知道其是 buf中截取的片段,因此我们知道抓包的文件,与payload的值进行对比下。
打印r.payload的16进制,本地打开该文件(6077901_18_rtp_new),对比数据发现,payload确实是文件中的数据片段。如下图:
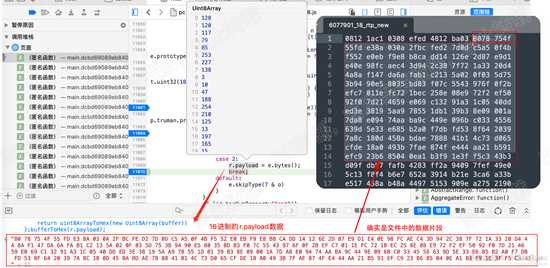
d26.png
d26
现在我们知道11860行的decode函数即是 解析npt和payload 数据包,并返回一个对象(含有npt和payload属性)
回到11940行 :
r.newPackets.push(p.truman.proto.ReplayRtpPacketNew.decode(e, e.uint32()));
可以知道,此代码即:将得到的npt和payload数据,放入newPackets数组中。
接下来我们直接到 11950行,并设置断点。放开其他断点,执行程序。查看此时r的值。如下图:
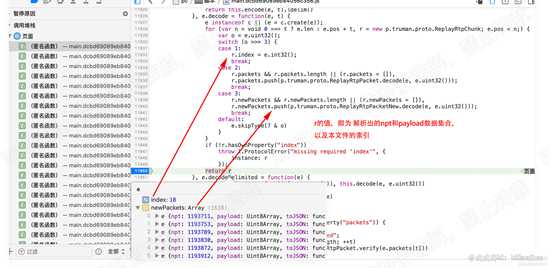
d27.png
d27
返回到115160行,在115161行设置断点,并执行。
var a = Iy.truman.proto.ReplayRtpChunk.decode(r);
查看a的值,即为刚才返回的r值。
由此我们知道:Iy.truman.proto.ReplayRtpChunk.decode(r);
该函数的作用是:将文件数据,按照一定的规则解码出其 npt和payload数据(其是rpt数据包)。
经过上述分析,我们可以找到一些数据规则:
a、所有文件以08开始,紧接着是文件的索引序号
b、从第3个字节开始解析npt和payload负载数据。
总结下:
以上分析,旨在理解一个文件数据是如何被解码拆分为多个数据包的。
接下来,我们就对数据包中payload数据(rtp包)进行分析,看其是如何继续拆包的
2.4 分析packet的payload(rtp包)数据解析
限于篇幅,我们直接到我们的目标代码处。
在115574行设置断点,解除其他断点,执行。程序停留在此行,我们查看参数e的值。
可以知道,其值就是我们刚解析的 文件的数据包数据。 这里是循环e中的数据,依次解码, 如下图:
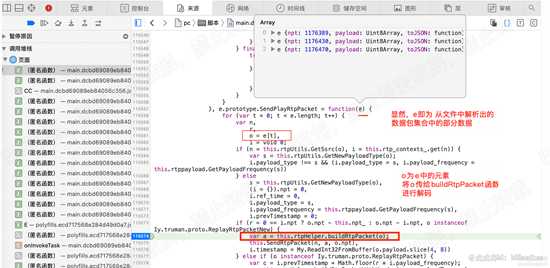
d28.png
d28
进入buildRtpPacket函数,并在103165行设置断点。执行程序,进入函数。
先简单了解下rtp协议的字段结构:
rtp包头固定12字节
版本号:2个bit
P: 1bit
X: 1bit 是否有拓展。X字段为1,说明后面跟着RTP Header Extension。
CC: 4bit
M: 1bit
PT: 7bit payloadType 负载类型
SN: 16bit 序列号
timestamp: 32bit
SSRC: 32bit
CSRC: 32bit
单步执行到103181行,查看i的值,i即为rtp包的payload. 分析下解码的过程,如下图:
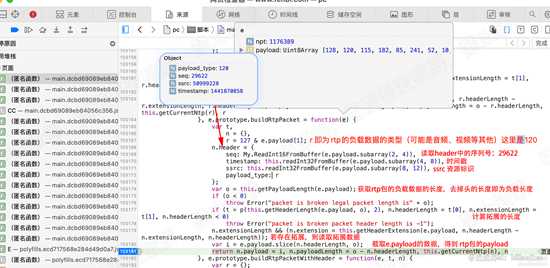
d29.png
d29
返回115575行,设置断点,执行。 查看a的值。 可以看到刚刚解析的 rtp的头和负载数据等。
查看 this.rtpHelper.payloadRegister.payloadMap 的值,可以看到payloadType为120
的类型是 opus 数据类型。如下图:
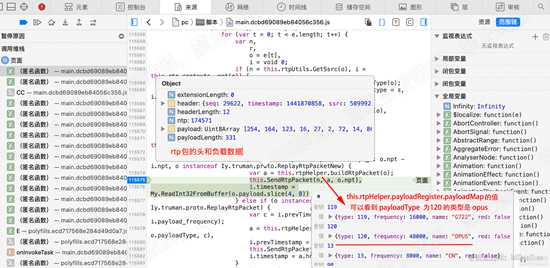
d30.png
d30
数据结构分析过程完毕了,详细的数据说明我们放在第三部分,接下来,我们分析如何提取音频。
2.5 如何提取音频
刚才我们已经接触到我们的rtp的payloadType为opus了,现在我们简介下opus。
opus是一种音频编码压缩方式,将原始的音频PCM数据,经过opus的特有算法进行编码。
opus编码的文件在低码率上具有更好的质量。简单说就是 又小又清晰。这也是为什么即时通讯需要使用它了。
关于opus知道这么多就足够了。
我们现在已经知道 rtp的负载数据类型为120的,即为opus数据,那么我们把所有的opus的数据合并,然后存成文件不就可以了吗?
理论上确实可以的。起初我也这么干了,可惜播放不了。经过百度,得知,我们rtp携带的是opus的裸流,不包含其包头等信息,所以直接
合成文件不可以播放。若需要播放,还需要添加opus头,因此编码起来比较麻烦,还需要自己组header。太麻烦。
经过一番搜索后发现,这里是将opus包解码成pcm 然后将pcm组装进 播放器进行播放。
那么思路又来了,我们将编码后的pcm组合到一起,然后编码成文件,不就导出音频了吗。
上操作,失败,不能播放,原因,缺少pcm头。这个相对来说简单些。于是,查询wav的头结构,编码添加到pcm数据文件上。
难以置信成功了。
下面看下opus解码的部分。
全局搜索handlePcmData,定位到 108092行函数,设置断点,执行到此处。
观察参数a的值,可以看到,a就是上面我们解码出的rtp包的数据,a.payload 即为rtp的负载数据(这里是opus数据),
同时看到解码出的f的数据为3840长度的数组,这是双声道的数据,如图
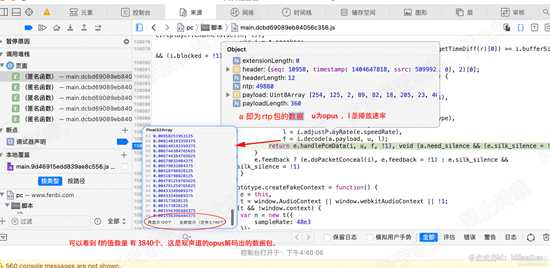
d31.png
d31
可以知道108091行的代码 f = i.decode(a.payload, u, l);就是解码opus的函数。
我们只要将f的数据合并,然后添加wav头,保存成文件,就可以播放了。
关于如何添加wav头,这里就不再复述。可参考demo。
总结下:
提取音频似乎很简单。应了那句话,会了的都不难。
a、找到opus解码后的pcm数据
b、将pcm合并,并且添加header,保存即可。
3 抓包的文件数据结构解析
这里以 6077901_6_rtp_new 文件作为示例。文件我会一起放在demo中。
每个文件由 1字节的标识符 和1字节的索引,
以及 n个数据包(由npt和rtp包组成),
rtp中的payload数据 即是媒体数据,这里是opus。
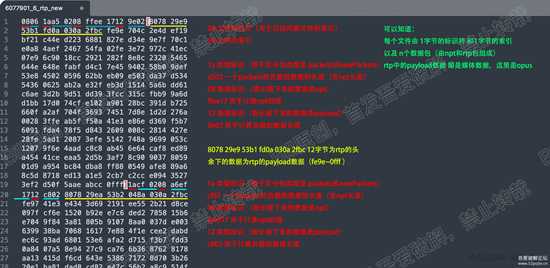
d32.png
d32
4 提取代码实现
根据上文的思路,我们首先读取文件,并解析出所有npt和payload数据。
此处,将decode函数单独抽离,封装到一个js文件中。demo中是decode-audio.js
通过 decode-audio-loader.js 调用decode方法。decode调用如下:
let nn = abc([]);
//解码数据得到npt分组数据
let e = nn['cU4B'].exports.truman.proto.ReplayRtpChunk.decode(new Uint8Array(data));
//得到解码的数据
let datas = e.newPackets;
循环解析rtp包中的payload,同时解码解析出opus包
this.totalSampleCount = datas.length;
for (var j = 0; j < datas.length; j++) {
//解析RTP数据包(得到header和payload),这里的payload 即为原始的opus数据包了let rtp = buildRtpPacket(datas[j], this.opusSampleRate);let opusPacket = rtp.payloaddecodeOpusPacket(opusPacket);}
在decodeOpusPacket中,会将opus解码出的pcm拼接并保存。
//拼接pcmData,并拆分数据到左右声道
bill_appendData = function(pcmData) {
///bill_add 本函数我写的var len = pcmData.length / 2;if (!this.sampleLen) { this.sampleLen = len;} else { this.sampleLen += len;}if (!this.leftData) { this.leftData = [];}if (!this.rightData) { this.rightData = [];}var i = 0;for (i = 0; i < len; i++) { this.leftData.push(pcmData[i * 2]) this.rightData.push(pcmData[i * 2 + 1])}